Vårens grönska
Denna månad, centralt för våra bilder är något som kallas NDVI-index och bilden baseras på observationer från Sentinel-2A satelliten. För att förklara NDVI, låt oss gå tillbaka till de grundläggande principer som vi har diskuterat tidigare. Sentinel-2-satelliter sparar mängden elektromagnetisk strålning på flera olika vågband, med deras MSI-instrument, som illustreras på bild 1. Normalt, för att få samma bild som vi skulle få om det skulle vara en vanlig kamera monterad på satelliten, skulle vi använda den elektromagnetiska strålningen som sparas i banden 4, 3 och 2 för mängden röda, gröna och blå färger i bilden (så kallad RGB-bild). Om ni minns från de falska färgsamtalen tidigare, så kan vi använda andra band för att representera mängden färg för rött, grönt och blått, varje gång vi ser något som vi inte kan observera från en ”normal” bild.

Bild 1. Klicka för att förstora.
Med index i fjärranalys menar vi något som beräknas med värdena i olika band. Beräkningen i sig kan ta många olika former. Det finns många sätt att undersöka relationerna mellan siffrorna som Sentinel-2 satelliten har sparat för olika band i samma område. Bilder på din skärm består av pixlar, små fyrkanter eller rektanglar som vanligtvis är så små att du inte kan se dem. Detsamma gäller för Sentinel-2-bilderna, du kan föreställa dig bilden som består av ett rutnät som placeras över det område som satelliten ser. Till exempel, i bild 2 kan du se denna typ av rutnät placerat över idrottsplatsen i Vörå. Dessutom visualiseras i samma bild idén om hur Sentinel-2 sparar elektromagnetisk strålningsinformation för varje pixel för varje band. Detta är en förenklad visualisering, eftersom ”pixelstorleken” i verkligheten är annorlunda för några av banden, men vi kommer att prata mer om det i kommande samtal. Också siffrorna är i verkligheten i en lite annorlunda form.
Bild 2.
Ett av de enklaste knepen för att illustrera konceptet kan vara snödetektering. Med Sentinel-2-data kan du ta värdet av band 3 och dela det med värdet av band 11:
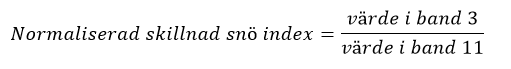
Om förhållandet är högre än 0,42 är det området vanligtvis täckt av snö. Varför fungerar det här? Jo, eftersom det är skillnader i reflektion i olika våglängder för olika typer av saker, som vi har diskuterat i tidigare samtal. Här tittar vi på band 3 och 11, vilket betyder att våglängderna är centraliserade vid omkring 560 nm och runt 1610 nm, och undersöker särskilt reflektionen i band 3. Snön reflekterar tillbaka mycket mer i det våglängdsområdet än bara jord, medan reflektionen vid band 11 är relativt densamma för snötäckt mark och bar mark. Vi kan sedan testa med den enkla uppdelningen nämnd ovan: med exemplet så skulle siffrorna på band 3 vara 30, och band 11 skulle vara 30 i den pixeln. 30/30 är 1, så vi kan då misstänka området som pixeln täcker skulle vara snötäckt. Vi kan också spara den informationen för vidare användning och göra det för alla pixlar. Resultatet skulle vara något som här i bilden 3, vårt exempel pixel markeras i grönt.

Bild 3.
Nu har vi ett nytt 6x6 ”bord” som också kallas en matris. Alla 2D-bilder kan ses som matriser. För varje cell har vi resultatvärdet för snötestet, och varje cell är relaterad till pixeln i originalbilden. Nu kan vi färga den här bilden baserat på dessa nya värden. Som i bild 4. Vi har färgat bilden så att pixlarna med högre förhållanden är färgade med ljusare toner, ser mer ut som snö. Lägre förhållanden, där det finns lägre risk för snö baserat på uträkningen, är mörkare.
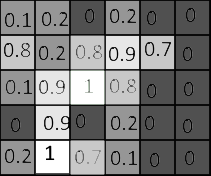
Bild 4.
Och slutligen tar vi bort siffrorna för tydlighets skull, som i bild 5 nedan. Vad vi har efter denna typ av process, är något vi kan säga är en snösannolikhetsbild. För denna nya sparade information, ett mycket grovt och förenklat snöindex, kunde vi ha valt färgvärdena hur vi än önskar. Vi valde något som relaterade till temat, vit som snö för högre sannolikhet för snö och mörkare för frånvaro av snö.

Bild 5.
I bilden som publiceras i Mega tidningen denna vecka, som visas här nedan i bild 6, har vi två bilder från olika tidpunkter från samma område (Vörå) och NDVI beräknat för båda. Vi har genomfört en process som liknar den vi beskrivit ovan. Istället för ett snörelaterat index använde vi ett index som fastställde mängden grön vegetation i varje pixel, sparade den indexinformationen för alla pixlar och använde sedan gröna nyanser för att färglägga de olika värdena. Resultatet av denna process visas som längst till vänster och bilden i mitten.

Bild 6. Klicka för större bild.
NDVI-index som vi använde kallas Normalized Difference Vegetation Index. Precis som snöexemplet är det baserat på skillnaden mellan reflektion och absorption på två våglängdsområden. Gröna blad innehåller klorofyll som absorberar starkt rött ljus. Å andra sidan reflekterar strukturen hos de gröna bladen starkt nära infrarött ljus. Baserat på denna skillnad kan vi beräkna ett index som visar höga värden på de områden där det finns mycket levande grön vegetation. Ekvationen är som följer:
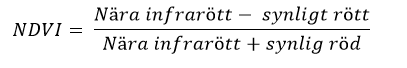
I vårt exempel använde vi band 4 (röd) och band 8 (nära infraröd). Som ett resultat fick vi ett stort bord (matris) som innehöll värden från -1,0 till 1,0, ett värde för var och en av pixlarna i bilden. Negativa värden är mestadels vattenområden (du kan se dem i vitt i vår bild) och värden nära 0 har ingen grön vegetation. När värdena går högre blir mängden grön vegetation också högre. Vi valde sedan att färga dessa värden med en skala där de mörkare gröna representerar områden med högre NDVI-värden. Som ni kan se motsvarar det ganska fint till skogarna och fälten med växande grödor. Även i centrum av Vörå kan man se betydande skillnad mellan de två bilderna, eftersom gräset i trädgården har vuxit under tidsskillnaden på en månad och en vecka mellan bilderna togs. NDVI är användbart för dessa typer av skogsbruk och jordbruksändamål.
Men den sista bilden till höger, den med svart, röd, gul och blå? Det är en ”skillnad” bild. I bild 7 nedan kan du se idén och processen förenklad. Vänster och mitt bilden motsvarar de verkliga bilderna där vi beräknade NDVI. I dessa finns ett NDVI-värde för varje pixel. För högre värden använde vi mörkare grön eftersom dessa områden har mer grön vegetation. Nu subtraherar vi NDVI-värdet för varje pixel i den tidigare bilden, från NDVI-värdet för samma pixel i den senare bilden. Det kommer att ge oss skillnaden mellan NDVI-värden. Resultatet av beräkningen lagras i en ny bild, för varje pixel. Till exempel, i övre vänstra hörnet, från 0.9 — 0 = 0.9, och 0.9 lagras i ny bild. Eller, på samma sätt nedre högra hörnet: 0.2-0.9 = -0.7, och -0,7 lagras.
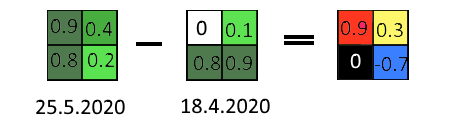
Bild 7.
Nu vet vi vad värdena betyder i skillnaden bilden. Noll eller nära noll innebär att det inte har skett någon större förändring i NDVI mellan datumen i området som täcks av den här pixeln. Höga värden innebär att under tiden mellan bilderna är tagna har det skett mycket grön vegetationstillväxt. Negativa värden innebär att mängden grön vegetation har minskat under tiden mellan bilderna. Vi valde olika färger för att representera dessa olika typer av förändringar. Vi använde rött för stora ökningar av grön vegetation, gult för mindre ökningar, svart och grått för områden utan betydande förändring och blått för de områden där vegetationen har minskat. Om du nu zoomar in till huvudbilden, tittar i alla bilder på de områden som är i rött eller blått, bör du kunna se fält som har vuxit mycket och vilka som redan har skördats.